Software Defined Networking and Programmable Networks
Traditionally network switches and routers have based on stand-alone implementations with vendor-specific user interfaces, where the data plane (processing of packets) and control plane (control and decision making logic) have been tightly coupled inside the vendor-specific implementation. High-performance routers and switches may have been based on custom ASICs (application specific integrated circuits), which makes it slow to introduce new features. As a result, the core Internet has become “ossified”: it is difficult to introduce new features that require network modifications, because deploying the changes to devices from different providers is slow.
These days large portion of the Internet communication and applications used in the Internet are hosted in massive datacenters, where the resources are leased to different customers (tenants) and dynamically scaled based on current needs. Different tenants have different requirements about the capacity, performance and quality of service of the network communication, and the network sections of different tenants need to be isolated so that they do not disrupt other users of the datacenter network and other resources.
Managing the network in the datacenter environment would be practically impossible to be done manually, as the network configuration in the massive network is very dynamic and changes constantly. Therefore the operation needs to be automated. This has led to development of Software Defined Networking (SDN), where the network switches have become programmable, and accessible through open APIs. The network operators can then implement high-level control logic that have a global view of the network status, and can react to changes in the network environment, and constantly do adjustments to the network switch processing logic through the APIs.
Related assignment: “eBPF traffic monitoring”
Network virtualization
Virtualization of computation and networks is an important enabling technology allowing cloud computing and datacenter networks to exist. Thousands of computer hosts are organized hierarchically using network switches. Each host contains virtual machines or containers with their dedicated IP addresses, belonging to different tenants using the datacenter. The node runs a virtual switch, most likely Open vSwitch (OVS) that it commonly used in Linux systems whenever virtual machines or containers are hosted in the system. The actual fast path packet switching happens in Linux kernel, but there is a userspace daemon (ovs-vswitchd) that controls the switching logic and communicates with the controllers that set up the switch tables.

For isolation, the virtual and physical hosts in the same physical network may be separated into virtual LANS (VLAN) that each have a VLAN identifier. The ports in single switch can be assigned to different VLANs, and VLANs can span across multiple switches through trunk connections. This way the hosts in the same VLAN can operate as if they were in a single isolated local network, even if they are actually connected to different points in the network. The IEEE 802.1Q VLAN specification defines an encapsulation format for the Ethernet frames.

The VLANs have their limits for very large datacenters, for example the VLAN identifier is just 12 bits long (allowing 4096 different values). In large datacenters Virtual extensible LANs (VXLAN) are therefore used. VXLAN has the same idea, but it encapsulates the Ethernet frames into UDP/IP packets, which allows more distributed LAN virtualization. VXLAN endpoint identifiers are also 24 bits long, which is sufficient for large networks.
SDN Architecture
Whereas the traditional network devices have combined the data plane forwarding and control logic into a single device with vendor-specific controls, software defined networking separates the different responsibilities into three layers, connected with open APIs.
The data plane takes care of per-packet processing at line rate, based on match-action rules controlled by an external controller. Data plane makes only local packet-by-packet decisions based on minimal state information and does not have global view of the network.
The control plane computes the forwarding decisions based on routing algorithms it runs, and maintains a view of the network topology. It may also compute rules based on traffic engineering and load balancing, and implement different policy rules. The control plane translates the high level intent and instructions from the management plane into flow rules that it installs to the switches operating on the data plane using the Southbound API. Conversely, the data plane devices can deliver metrics and packet-level statistics to the control plane using this interface. Even though logically control plane is a centralized entity managing the global view of the network, on large networks it can be distributed.
The management plane takes care of the high level configuration and monitoring of the network, and user interaction. On management plane the network policies and rules are defined on a high level, for example, the traffic engineering and policing goals for the different users of the network, and needs for different isolation domains. These high-level intents are communicated to the control plane using the Northbound API (that could be, e.g., REST API).
This logical separation different planes using open APIs should allow for vendor-independent configurations: network switches could be of different brand implementing the specification, and the controller and management software could be acquired from independent provider.
The below figure is linked from article “Software-Defined Networking: the New Norm for Network” by Open Networking Foundation.

Further reading
- N. Feamster, J. Rexford, E. Zegura. The road to SDN: an intellectual history of programmable networks. ACM SIGCOMM Computer Communication Review, vol. 44, n. 2, April 2014. Note that this article was published more than 10 years ago, and technology on programmable networks has evolved since then.
- Nunes, et. al. A Survey of Software-Defined Networking: Past, Present, and Future of Programmable Networks. IEEE Communications Surveys & Tutorials, vol. 16, n. 3, Q3 2014.
OpenFlow
When the ideas of SDN networks emerged, OpenFlow was the first (southbound) API specification to communicate flow rules and statistics between network switches and control software. An OpenFlow-capable switch contains flow tables with match-action rules against which the incoming packets are processed, and a decision on the packet is made. Various fields from layer 2, IP or transport headers are available for the match rules, for example VLAN identifier, source or destination IP addresses, on transport ports. Possible actions can be, for example, forwarding to particular outgoing switch port, dropping the packet or passing it to controller for further processing.
The controller software connects to OpenFlow switches using a TLS-protected TCP connection, and uses this connection to enter match-action rules and collect statistics from switch.
One limitation of the OpenFlow specification is that the match rules are based on predefined protocol fields of the currently used protocols. It does not support experimentation with new protocol solutions, an therefore does not really help in solving the ossification problem of the core Internet protocols. It also has had scalability problems in production networks, where the match-action tables tend to grow large. There are also some performance bottlenecks: if the current match-action rules do not cover incoming packet, an OpenFlow switch passes the packet decision to the controller, which adds delay to the packet processing. Therefore OpenFlow did not gain wide-spread deployment in production networks. It was among the first SDN solutions however, and still in use for some academic and education purposes, for example with the Mininet emulator.
The below figure is linked from the same source than above. It illustrates a simplified flow table from an OpenFlow-compatible SDN switch

P4: a Programmable Data Plane
Whereas traditional switches or OpenFlow are limited to predefined fields and actions, a programmable data plane can operate on entire packet headers and define flexible custom actions on packets, and can handle even new protocols instead of traditional Internet protocols.
P4 is a programming language for specifying header formats, packet matching rules and actions on them. It defines a high-level common imperative language that can be compiled into a form that different switch hardware and other network devices can process at line rate. Using such language the programmer can just define the packet processing logic without having to care the different switch designs.
P4 processing is split into different stages. First, the packet headers are parsed using the provided parsing code. Then they are organized into match-action tables that process the packet headers based on give rules, and take action as determined by programmer. Matching is done separately both for incoming (ingress) packets, after which they are placed in a queue. Then, there may be separate actions for outgoing (egress) packets coming out of the queue. Actions could be, for example, forwarding decisions, dropping packets, or modifying the headers in some way. The figure below illustrates these phases. It is linked from “Security Middleware Programming Using P4” by P. Vörös and A. Kiss.
The P4Runtime works as the controller in the P4 system, that will feed the actual match-action rules into the P4 pipeline, after carrying out the control plane functions as discussed above.
The specifications of P4 language, and other related documentation are publicly available.
There are P4 tutorials in the Github, to demonstrate various applications that can be run in a P4 device.
Further reading
- P. Bosshart, et. al. P4: programming protocol-independent packet processors. ACM SIGCOMM Computer Communication Review, vol. 44, n. 3, July 2014.
- E. F. Kfoury, J. Crichigno, E. Bou-Harb. An Exhaustive Survey on P4 Programmable Data Plane Switches: Taxonomy, Applications, Challenges, and Future Trends. IEEE Access, vol. 9, June 2021.
Extended BPF (eBPF)
Extended BPF (eBPF) is another programmable way to process packets at higher speeds, particularly in Linux kernel. eBPF allows running small programs inside kernel in a safe, sandboxed way. Unlike with Netfilter hooks, the eBPF programs can be implemented, compiled and installed at runtime, without recompiling or rebooting the Linux kernel. There are different hook points where eBPF programs can be attached, for example in different points of packet processing in the networking stack. eBPF therefore enables high-performance packet processing, tracing, security enforcement or load balancing in a dynamic way. eBPF is used particularly for cloud networking use cases, e.g., in Kubernetes clusters, to support fast packet processing without spending unnecessary processing cycles in virtual machines or containers.
An eBPF program is typically implemented in C source code, which is the compiled into eBPF byte code (which is different from normal executable binary). The byte code is then installed to kernel by using a loader program. The kernel runs the code through verifier and Just-in-Time compiler, checking that the memory handling is safe and that the program cannot block the other kernel operation. User-space programs can interact with the eBPF program through libbpf library, and special data structures, or key-value “maps”. The Maps can be used to deliver, for example, packet data to userspace (Wireshark uses this), or instructions from user space to kernel program (e.g. list of blocked IP addresses).
The below picture is linked from eBPF introduction by the eBPF Foundation and illustrates the development and processing workflow.
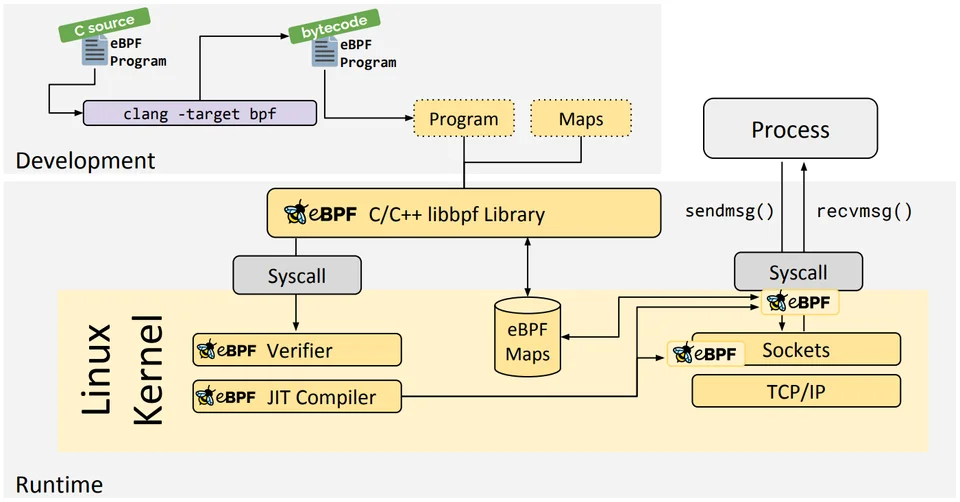
Express data path (XDP) is one of the hook points particularly useful in networking. It installs the program at the network device driver level, at a point where processing of incoming starts. At this point even the skbuff has not yet been built. XDP program can, for example, modify the packet headers, or decide to drop it. Measurement studies show that it is significantly faster to process packets in XDP than in the Netfilter hooks, that come at a later stage of packet processing, making it useful, for example for countering DDOS attacks at high speeds. XDP only processes incoming packets from the network device.
Another hook for network programmers is the Traffic Control hook that can process outgoing packets, for example by defining alternative queueing heuristics or some support for differentiated Quality of Service, e.g. based on traffic type.
eBPF example
You can try eBPF in your own Linux machine (or virtual machine) quite easily, just by installing the needed development packages that are available in most common Linux distributions. xdp_prog.c contains a simple XDP program that drops all ICMP/IPv4 packets, but forwards other protocols.
First, install the needed compile and build tools and libraries for eBPF (some of these might be installed already)
1
2
3
sudo apt update
sudo apt install build-essential clang llvm linux-libc-dev
sudo apt install bpftool libbpf-dev
Typically eBPF programs are written in C (although there are also tools to compile eBPF programs from Rust source) and then compiled to a binary object code. A separate loader userspace loader program is then used to load the code to kernel-side eBPF virtual machine that executes the program near the device driver as packets are received. See the code commentary for more detailed description what happens.
The XDP/eBPF programs are compiled using Clang and LLVM tools, like in this case:
1
clang -O2 -g -Wall -target bpf -c xdp_prog.c -o xdp_prog.o
Additionally, we’ll need to write a separate loader program, loader.c, that installs the compiled XDP binary and uses the userspace libbpf library to interact with the code from the userspace application.
Compile loader that installs xdp_prog.o to the network interface driver:
1
gcc -O2 -Wall loader.c -lbpf -o loader
Execute the program, and on other window try what happens with ping packets. You can compare this to TCP packets, for example by trying HTTP request with wget or curl.
1
sudo ./loader
Further reading
- M. Vieira. Fast Packet Processing with eBPF and XDP: Concepts, Code, Challenges, and Applications. ACM Computing Surveys (CSUR), vol. 53, n. 1, February 2020.